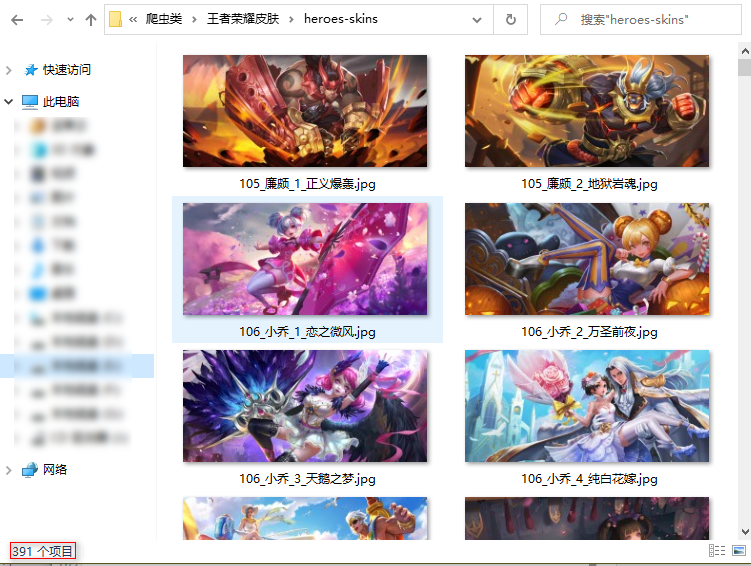
今天来一个爬虫实战,目标是王者"农药",哦不是王者荣耀的英雄全皮肤下载。
我们用10行代码下载98个英雄的341个皮肤,当然这个是初级版代码,而且不是全部皮肤。
升级版我们会用20行代码下载真正的最新全皮肤-391个皮肤。话不多说让我们开始吧!
目标分析
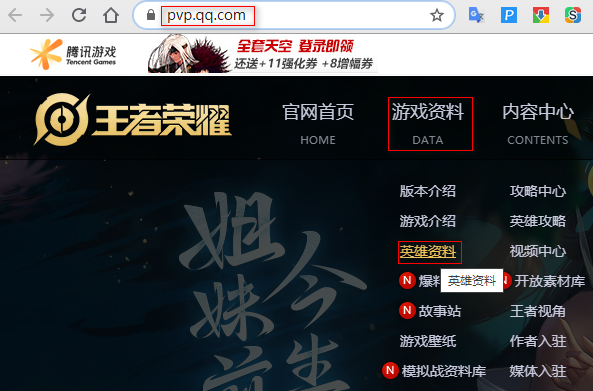
我们进入王者荣耀官方网站https://pvp.qq.com/,点击游戏资料 -> 英雄资料。
打开控制台,刷新网页,分析有哪些请求.选择XHR请求,我们发现有一个json请求,herolist.json,看名字就是英雄列表,打开一看果不其然。
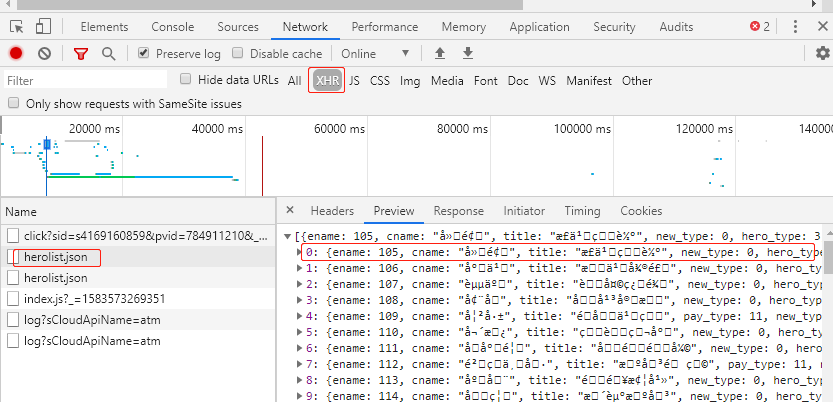
因为是GBK编码使用在控制台查看是乱码,下面我给一个英雄的数据。
1
2
3
4
5
6
7
8
|
{
"ename": 106,
"cname": "小乔",
"title": "恋之微风",
"new_type": 0,
"hero_type": 2,
"skin_name": "恋之微风|万圣前夜|天鹅之梦|纯白花嫁|缤纷独角兽"
}
|
分析一下数据:
| 字段 |
说明 |
| ename |
英雄编号 |
| cname |
英雄名称 |
| skin_name |
拥有的皮肤 |
我们发现小乔有5个皮肤,每个皮肤的名称以|分隔。
我们继续点开小乔英雄查看皮肤地址。转跳的地址是https://pvp.qq.com/web201605/herodetail/106.shtml,发现地址中的106就是英雄的ename字段。多试几次就可以确定了,以我们可以直接拼接这个URL。
我们可以看到小乔有6个皮肤,就是说herolist.json里面的数据不是最新的。

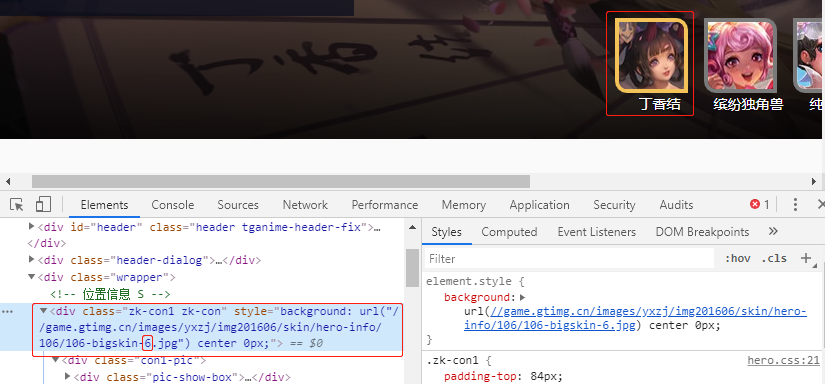
我们元素审查一下元素查看背景图片。鼠标指向最左边的皮肤看到图片地址为:
//game.gtimg.cn/images/yxzj/img201606/skin/hero-info/106/106-bigskin-6.jpg
同样的道理106可能是ename,多点几个英雄可以确定。看到小框的6了吗,推测应该是第六个皮肤的意思,鼠标拖动到其他皮肤就可以发现是这个意思。
分析到这里我们可以实现代码编写了。
简单版的代码实现
1
2
3
4
5
6
7
8
9
10
11
|
import requests
img_url = 'http://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/{0}/{0}-bigskin-{1}.jpg'
for hero in requests.get('https://pvp.qq.com/web201605/js/herolist.json').json():
skin_names = hero.get('skin_name', '').split('|')
for index, skin_name in enumerate(skin_names, 1):
file_path = f"{hero['ename']}_{hero['cname']}_{index}_{skin_name}.jpg"
img_result = requests.get(img_url.format(hero['ename'], index))
with open(file_path, 'wb') as f:
f.write(img_result.content)
# 共计 341 个皮肤
|
代码解读:
4L:直接获取herolist.json数据进行循环遍历
5L:以|分隔每个英雄的皮肤名称
6L:遍历皮肤名称列表
8L:拼接皮肤图片的URL,进行下载
9L:写入到文件
共计下载341个皮肤。
前面也提及到herolist.json里面的数据不是最新的,所以新出的皮肤是没有下载的,因此只有341个皮肤。
升级版的代码实现
有上面的问题,我们不用herolist里面的皮肤数据,而是到详情页,获取最新皮肤数据。分析网页详情发现皮肤数据在ul的data-igname=xxx,同样以|分隔,但是多了&数字的内容,我们把它处理一下就可以使用了。
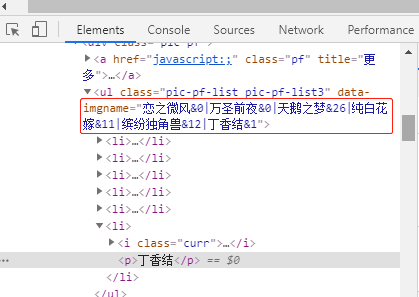
请看代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
import re
import requests
url = 'https://pvp.qq.com/web201605/herodetail/%s.shtml'
img_url = 'http://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/{0}/{0}-bigskin-{1}.jpg'
for hero in requests.get('https://pvp.qq.com/web201605/js/herolist.json').json():
result = requests.get(url % hero['ename'])
result.encoding = 'gbk'
t = re.findall('data-imgname="(.*?)"', result.text)
# 苍天翔龙&0|忍●炎影&1|未来纪元&1|皇家上将&6|嘻哈天王&1|白执事&1|引擎之心&5"
skin_num = re.sub('&\d+', '', t[0]).split('|')
# 抓取图片到本地
for index, skin_name in enumerate(skin_num, 1):
img_result = requests.get(img_url.format(hero['ename'], index))
file_path = f"{hero['ename']}_{hero['cname']}_{index}_{skin_name}.jpg"
with open(file_path, 'wb') as f:
f.write(img_result.content)
print("下载皮肤", index, file_path)
# 共计 391 个皮肤
|
前面代码和简单版的一样,获取herolist.json数据
8-12L:使用ename拼接英雄详情页URL,从中解析出皮肤名称,并清理。
后面的和简单版一样拼接皮肤图片URL,并下载到本地。
共计下载391个皮肤,118.7MB。
每张皮肤图片都很清晰。

代码地址:
https://github.com/niaiai/wx_code/tree/master/爬虫类/王者荣耀皮肤
如有需要皮肤图片在公众号回复王者荣耀皮肤,即可获得皮肤图片的分享链接。
